Startup's tool aims to help companies decide which AI is right for them

Add Axios as your preferred source to
see more of our stories on Google.
A screenshot of Arthur Bench evaluating various generative AI systems. Image: Arthur
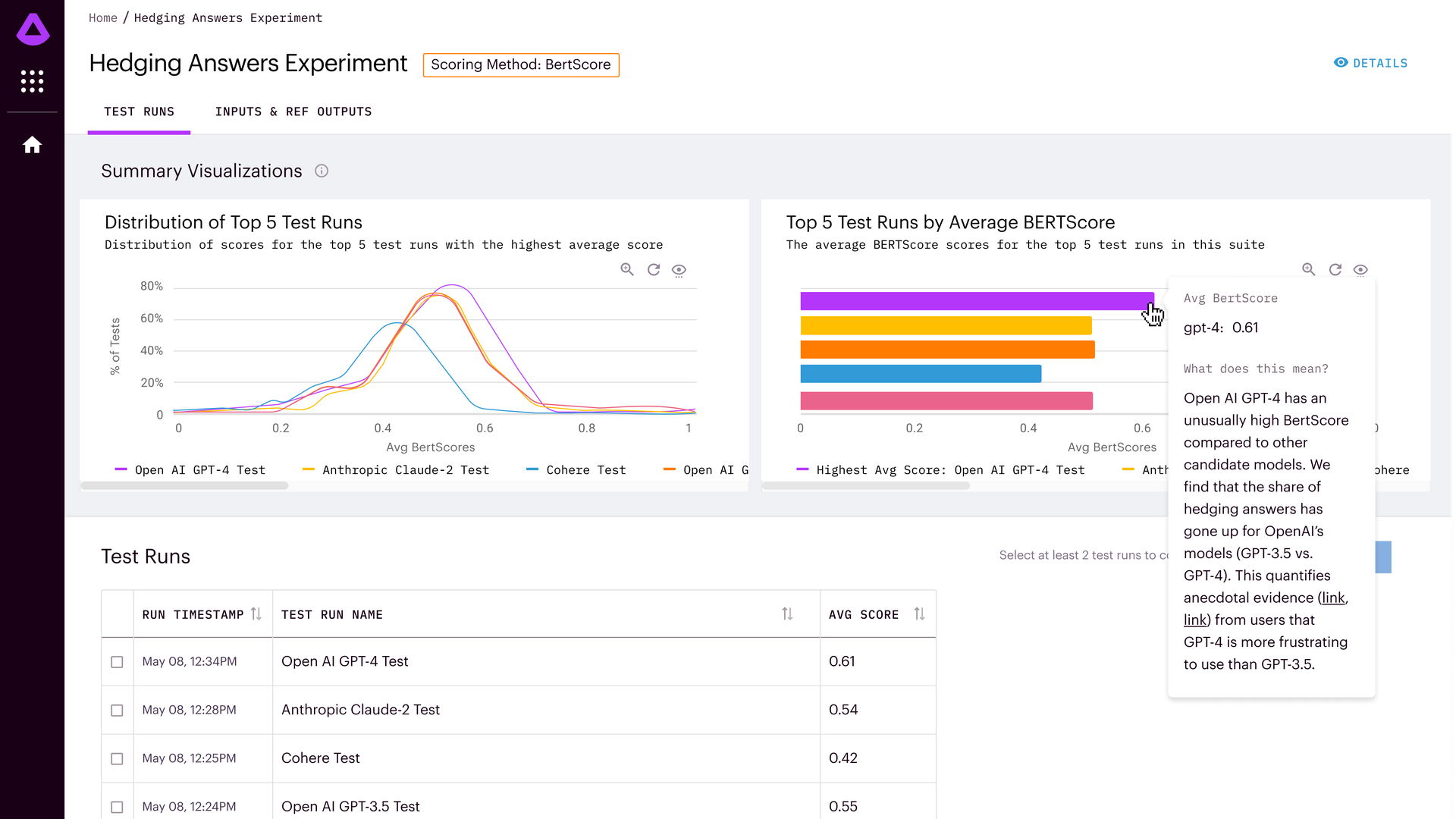
OpenAI remains the leader in generative AI, but its rivals have narrowed the gap and may be a better option for certain uses, a new AI assessment tool has found. The open-source testing platform released Thursday by startup Arthur aims to help businesses figure out which large language model is best suited to their needs.
Why it matters: Given the types of results produced by generative AI — and the fact that answers can differ over time — it is often hard to quantify or even decide which generative system is best for a particular task. Arthur's tool appears among the first to make such recommendations
Driving the news: Arthur, a New York-based startup, is using the open source tool Arthur Bench to launch the Generative Assessment Project, an ongoing effort to measure the effectiveness of different generative AI tools.
- Its first assessment found that OpenAI's GPT-4 leads among the major systems.
- But it also observed that, in certain circumstances, Anthropic's Claude 2 proved less likely to "hallucinate," or make up false information.
- Cohere's Command, meanwhile, was less likely to reject a query as beyond its capabilities though it rarely was able to correctly answer the complex questions Arthur put forth in its tests.
How it works: Arthur tested OpenAI's GPT-3.5 and GPT-4 along with models from Cohere, Anthropic and Meta, running each query three times to take into account the fact that a single model can provide different answers even when presented with the same question.
- The testing spanned three categories: combinatorial mathematics, U.S. presidents, and Moroccan political leaders. Each question required multiple steps of reasoning.
- Each answer was categorized as having either answered the query correctly, made up an incorrect answer or having avoided answering the question.
What they're saying: "OpenAI continues to perform very well, but there were some areas where some of the competitors have closed the gap," Arthur CEO Adam Wenchel told Axios.
- "There were definitely some surprises and nuances that were pretty interesting," Wenchel said.
Of note: Arthur says it deliberately used challenging questions that today's large language models often can't answer on their own. In practice, data scientists often fetch extra context, such as Wikipedia pages, in order to answer factual questions.
Between the lines: Given the nature of generative AI responses, deciding which system is best depends on what one is looking for. One system may be more concise, and another more comprehensive, for example.
