An AI learns to predict a scene from just one image

Add Axios as your preferred source to
see more of our stories on Google.
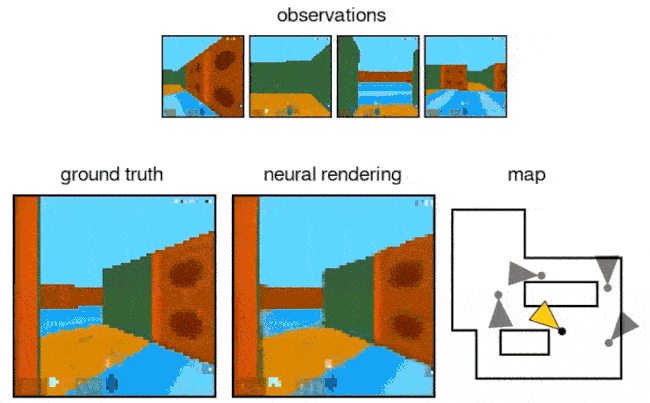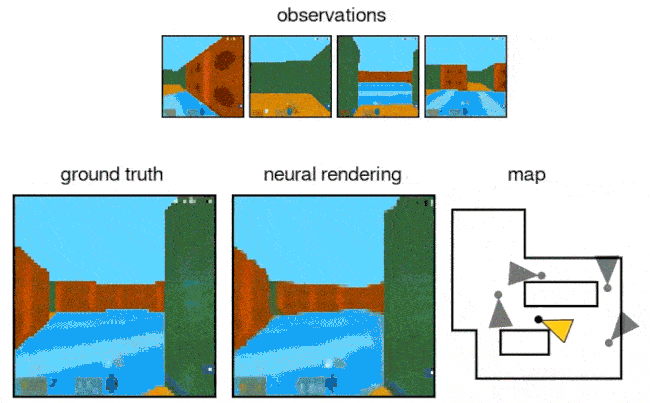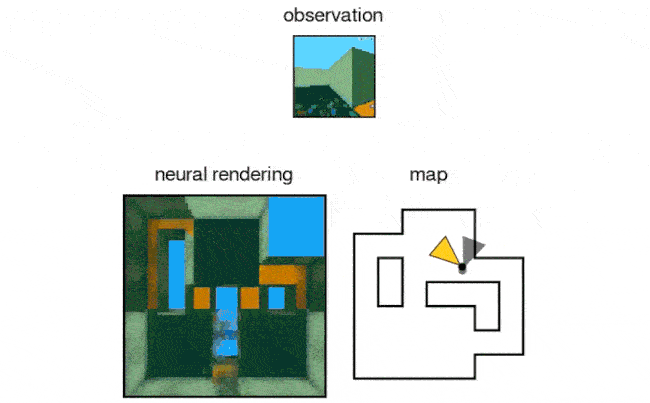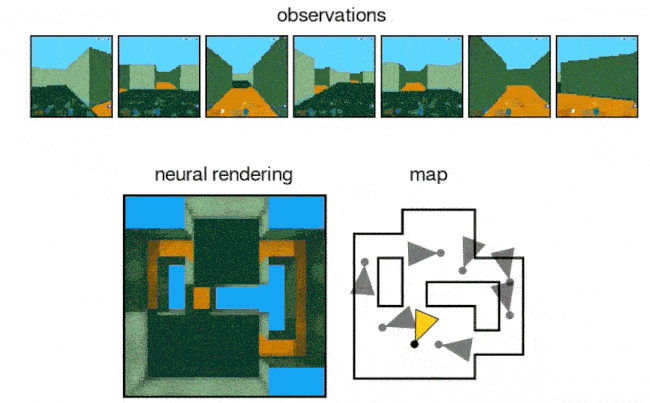
A machine learning system from Google's DeepMind can collect snapshots of a 3D scene taken from different angles and then predict what that environment will look like from a viewpoint it hasn't seen before, according to research published today in Science.
The big picture: Researchers want to create AIs that can build models of the world from data they've seen and then use those models to function in new environments. That capability could take an AI from the realm of learning about a space to understanding it — much the same way humans do — and is key to developing machines that can move autonomously through the world. (Think: driverless cars.)
The context: Computer vision — spurred by the availability of data and increased computing power — has rapidly advanced in the past six years. Many of the underlying algorithms largely learn via supervision: an algorithm is given a large dataset that is labeled with information (for example, about the object in a scene) and uses it to predict an output.
“Supervised learning has been super successful but it’s unsatisfying for two reasons. One, humans need to manually create the [training] datasets, which is expensive and they don’t capture everything. And two, it is not the way infants or higher mammals learn.”— Ali Eslami, study author and researcher at DeepMind
Instead, researchers want to train machines to learn from unlabeled inputs that they process without any guidance from a human, and then to be able to apply or transfer what they learn to other new scenarios and tasks.
How it works: The system uses a pair of images of a virtual 3D scene taken from different angles to create a representation of the space. A separate “generation” network then predicts what the scene will look like from a different viewpoint it hasn’t seen before.
- After training the generative query network (GQN) on millions of images, it could use one image to determine the identity, position and color of objects as well as shadows and other aspects of perspective, the authors wrote.
- That ability to understand the scene's structure is the "most fascinating" part of the study, wrote the University of Maryland's Matthias Zwicker, who wasn't involved in the research.
- The DeepMind researchers also tested the AI in a maze and reported the network can accurately predict a scene with only partial information.
- A virtual robotic arm could also be controlled by the GQN to reach a colored object in a scene.
Yes, but: These are relatively simple virtual environments and "it remains unclear how close [the researchers'] approach could come to understanding complex, real-world environments," Zwicker writes.
Harvard's Sam Gershman told MIT Technology Review the GQN still solves only the narrow problem of predicting what a scene looks like from a different angle. According to the article:
"Gershman says it’s unclear whether DeepMind’s approach could be adapted to answer more complex questions or whether some fundamentally different approach might be required."
The challenges: Eslami says it took a couple of months to train the network. “We really were pushing the hardware available to us to its limits. We need a step up in hardware capabilities and the techniques to build these deep neural networks and train them.”
Go deeper: Read more about the various ways researchers are trying to design AI to work like the human brain.
